
Text Detection and Extraction From Image with Python
Handy OCR and OpenCV technique to find text in digital image
This article will give you a glimpse of extracting text from digital images. We will use python and pytesseract library to extract the text. The image should have text inside it to find the output text.
The extraction of text with pytesseract needs a library to be installed in the system environment. The below commands will help the installation of libraries in your system.
To install the OpenCV library
pip install opencv-pythonTo install the pytesseract-ocr library
pip install pytesseractWe can also install the setup file of tesseract setup file to get the tesseract.exe file from the below link.
https://github.com/UB-Mannheim/tesseract/wikiDownload the above file as per the system configuration then install it. We will see the tesseract.exe file in the path as shown below:
C:\Program Files\Tesseract-OCR\tesseract.exe"Let's see the input image from which we need to extract the text.

In this python example, we will extract text from the grayscale image, and in the next example, we will extract the text from a color image with a bounding box.
Extracting text from a grayscale image
We need to import all the library that is required for this example.
from PIL import Image
from pytesseract import pytesseractNow we will use a pillow library to open/read the image.
image = Image.open('ocr.png')
image = image.resize((400,200))
image.save('sample.png')Observations:
- The open method is used to read the image from the working directory.
- The resize method is used to change the size of the image.
- The save method is used to save the image after changing the size.
Now we will define the binary file path of tesseract as shown below.
path_to_tesseract = r"C:\Program Files\Tesseract-OCR\tesseract.exe"
pytesseract.tesseract_cmd = path_to_tesseractIt's time to use the method image_to_string of tesseract class to extract the text from the image.
text = pytesseract.image_to_string(image)
#print the text line by line
print(text[:-1])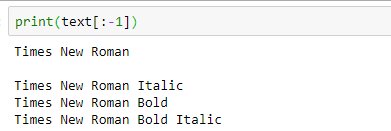
Detecting and extracting text from color image
In this section, we will extract the text from the color image. The sample color image is shown below.

In this example, we will use OpenCV also to use the bounding box and other methods for OpenCV.
Install the libraries for this example
import cv2
from pytesseract import pytesseractNow we will define the binary file path of tesseract as shown below.
path_to_tesseract = r"C:\Program Files\Tesseract-OCR\tesseract.exe"
pytesseract.tesseract_cmd = path_to_tesseractReading the image with the help of OpenCV method.
img = cv2.imread("color_ocr.png")Converting the color image to grayscale image for better text processing.
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)Now, we will convert the grayscale image to binary image to enhance the chance of text extracting.
ret, thresh1 = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU |
cv2.THRESH_BINARY_INV)
cv2.imwrite('threshold_image.jpg',thresh1)Here, imwrite method is used to save the image in the working directory.

To get the size of the sentences or even a word from the image, we need a structure element method in OpenCV with the kernel size depending upon the area of the text.
rect_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (12, 12))The next step is to use the dilation method on the binary image to get the boundaries of the text.
dilation = cv2.dilate(thresh1, rect_kernel, iterations = 3)
cv2.imwrite('dilation_image.jpg',dilation)
We can increase the iteration number, depending on the foreground pixels i.e. white pixels to get the proper shape of the bounding box.
Now, we will use the find contour method to get the area of the white pixels.
contours, hierarchy = cv2.findContours(dilation, cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_NONE)To do some operations on the image, copy it to another variable.
im2 = img.copy()Now, it's time to get the magic to happen on the image. Here we will get the coordinates of the white pixel area and draw the bounding box around it. We will also save the text from the image in the text file.
for cnt in contours:
x, y, w, h = cv2.boundingRect(cnt)
# Draw the bounding box on the text area
rect=cv2.rectangle(im2, (x, y), (x + w, y + h), (0, 255, 0), 2)
# Crop the bounding box area
cropped = im2[y:y + h, x:x + w]
cv2.imwrite('rectanglebox.jpg',rect)
# open the text file
file = open("text_output2.txt", "a")
# Using tesseract on the cropped image area to get text
text = pytesseract.image_to_string(cropped)
# Adding the text to the file
file.write(text)
file.write("\n")
# Closing the file
file.closeThe output of the bounding box image.

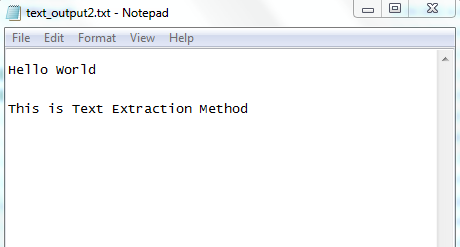
The result of the text file.
We noticed one thing when we have the iteration number is equal to 1 then the text didn't save in the text file, after increasing the iteration number to 3, we got the results.
If code is working properly and output is not coming then check or change the kernel size and iteration numbers.
To extract the image of each bounding box from the image.
crop_number=0
for cnt in contours:
x, y, w, h = cv2.boundingRect(cnt)
# Draw the bounding box on the text area
rect = cv2.rectangle(im2, (x, y), (x + w, y + h), (0, 255, 0), 2)
# Crop the bounding box area
cropped = im2[y:y + h, x:x + w]
cv2.imwrite("crop"+str(crop_number)+".jpeg",cropped)
crop_number+=1
cv2.imwrite('rectanglebox.jpg',rect)
# open the text file
file = open("text_output2.txt", "a")
# Using tesseract on the cropped image area to get text
text = pytesseract.image_to_string(cropped)
# Adding the text to the file
file.write(text)
file.write("\n")
# Closing the file
file.close
I hope you like the article. Reach me on my LinkedIn and twitter.
Recommended Articles
1. 8 Active Learning Insights of Python Collection Module 2. NumPy: Linear Algebra on Images 3. Exception Handling Concepts in Python 4. Pandas: Dealing with Categorical Data 5. Hyper-parameters: RandomSeachCV and GridSearchCV in Machine Learning 6. Fully Explained Linear Regression with Python 7. Fully Explained Logistic Regression with Python 8. Data Distribution using Numpy with Python 9. Decision Trees vs. Random Forests in Machine Learning 10. Standardization in Data Preprocessing with Python