
Querying Internal Documents using Mistral 7B with Context from an Ensemble Retriever
Could the lost quality of a quantized Mistral 7B model be redeemed with an ensemble retriever?
The exponential improvement in the text generation ability of Large Language Models (LLMs) is opening doors to almost unlimited possibilities. At the time of this writing, Mistral 7B and its variants occupy the Hugging Face leaderboard against similar sized models, and it is reported to outperform even much larger models. Even with such a performant pre-trained model, it may not perform well when asked questions about internal documents that the LLM may not have seen in its training. In such a scenario, there are two approaches to improve its performance, namely fine-tune the pre-trained LLM or supplement it with context from internal documents using retrieval-augmented generation (RAG).
In this article, we will explore the use of the Mistral 7B Instruct model with the RAG approach to use an ensemble retriever to capitalize on the different strengths of the retrievers for an improved overall question-answering (QA) system performance.
This article is structured as follows: 1. Key Enabling Technologies 2. System Architecture 3. Preparation of the Environment 4. Module 1: Load Document and Vectorize 5. Module 2: Load LLM and Create a QA chain 6. Module 3: Calculation of Sentence Similarity 7. Ensemble Retriever's Weights Ratio 8. Results and Findings
1. Key Enabling Technologies
Since Mistral AI introduced Mistral 7B model just a month ago, it has been downloaded more 200k times and received almost 1.5k likes. It is a 7-billion-parameter language model engineered for performance and efficiency. As per the creator, Mistral 7B outperformed Llama 2 13B across all evaluated benchmarks. They have also released a fine-tuned Mistral 7B Instruct model using publicly available conversation datasets. These models were released under the Apache 2.0 license, enabling anyone to fine-tune and harness its potential without restrictions.
Since the available system for me to experiment it is a MacBook Air M1 with 8GB RAM, it will be unable to load this model as is. Fortunately, quantization comes to our rescue. In essence, quantization involves representing the model's parameters using fewer bits, which effectively compresses the model. This compression results in reduced memory usage, faster execution times, and increased energy efficiency but at the compromise of the generation quality. On Hugging Face, TheBloke's repo offers GGUF format model files at 2-bit, 3-bit, 4-bit, 5-bit, 6-bit and 8-bit integer quantization support. To load such a GGUF model, we will be using the llama-cpp-python library, which is a Python bindings for the llama.cpp library
RAG integrates the power of retrieval into LLM text generation. This consists of a retriever system to fetch relevant document snippets from a corpus, and an LLM to generate responses using the retrieved snippets as context. In essence, RAG supplements the model with external information to improve the accuracy of the model's responses against local documents.
Since retriever is a major part of RAG, it has a significant influence on the overall QA system performance. LangChain, a well-known a powerful framework library to work with LLMs, includes the EnsembleRetriever that accepts a list of retrievers as input and ensemble the results, and rerank the results based on the Reciprocal Rank Fusion algorithm. By leveraging the strengths of different algorithms, it is expected to achieve better outcome than any one of them. The suggested pattern in the LangChain documentation is to combine a sparse retriever (like BM25) with a dense retriever due to their complementary strengths. The sparse retriever excels at identifying relevant documents based on keywords, while the dense retriever excels at finding based on semantic similarity.
With the identification of these libraries and model, we are now ready to build our system.
2. System Architecture
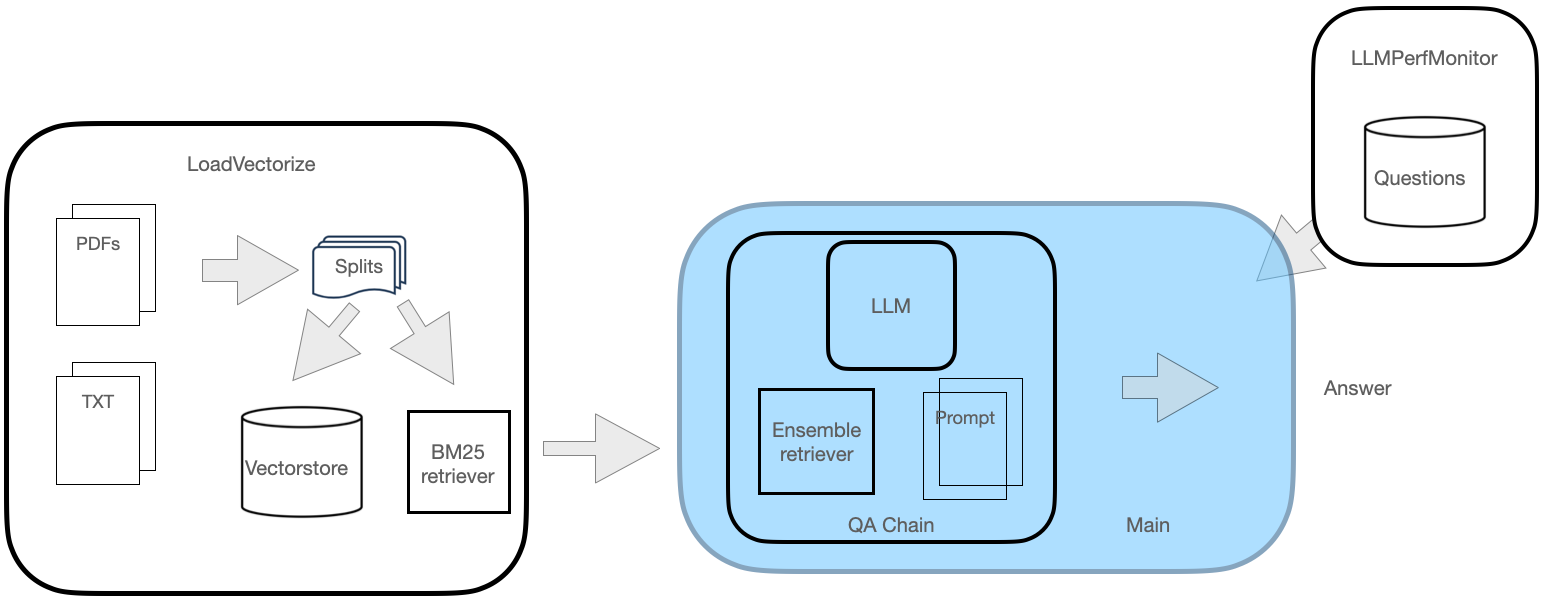
There will be two primary modules to realize this QA system as shown in Fig. 1. The first module involves loading an online pdf document. This document is then split at the selected chunk size, while allowing some overlap to maintain continuity between chunks. These chunks are subsequently used to create a vectorstore as well as a sparse BM25 retriever.
A second module will involve loading the Mistral LLM and creating an assemble retriever instance. It then creates a retrieval chain encompassing the LLM, the retriever and a custom prompt. At this stage, the chain is ready for querying.
Finally, a third helper module is also used to facilitate an objective measurement of the LLM performance across the questions by computing:
- sentence similarity - a measure of how similar two sentences are using cosine similarity and meteor score.
- execution time - the time in seconds of the interval from when the query is asked to the instant when a respond is received.
It will also load a list of questions along with the suggested answers that will be used for measuring accuracy.
Before we look at the code itself, let's briefly look at the setup of the environment.
3. Preparation of the Environment
My system is a MacBook with a M1 processor and 8 GB RAM. The version of Python used here is 3.10.5. We will create a virtual environment to manage this project.
To create and activate the environment, let's do the followings:
python3.10 -m venv mychat
source mychat/bin/activateWe can then proceed to install all the required libraries (which will also install quite a number of dependent libraries):
pip install langchain
pip install faiss-cpu
pip install rank_bm25
pip install sentence_transformers
CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 pip install --upgrade --force-reinstall llama-cpp-python --no-cache-dirTo use llama-cpp-python library with hardware acceleration on M1 processor, the above install command enables Metal support. Using Metal the computation runs on the GPU.
faiss-cpu is a library for efficient similarity search and clustering of dense vectors using CPU, instead of GPU. rank_bm25 also known as the Okapi BM25, is a ranking function to estimate the relevance of documents to a given search query. sentence-transformers provides easy methods to compute embeddings for sentences and others.
We are now ready to look at the code.
4. Module 1: Load Document and Vectorize
There will be 3 methods in this module. Method load_doc will load a specific online pdf document using OnlinePDFLoader and split it by certain chunk size with some overlaps between chunks. The sample document is a fairly recently released 600+ page guide of a vendor appliance, which I hope is not seen by the model during training.
The second method vectorize() uses the chunks to create a vectorstore, commits the index to disk to speed up future access as well as creates a BM25 retriever with the same chunks.
The final method load_db() serves as the interface for the main module of this system, where it attempts to load the vectorstore from disk if available, creates the BM25 retriever and returns both to the caller.
The following listing captures this module's code.
# LoadVectorize.py
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.document_loaders import OnlinePDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.retrievers import BM25Retriever
# access some online pdf, load and split
def load_doc():
loader = OnlinePDFLoader("https://support.riverbed.com/bin/support/download?did=b42r9nj98obctctoq05bl2qlga&version=9.14.2a")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=100)
docs = text_splitter.split_documents(documents)
return docs
# vectorise, commit to disk and create a BM25 retriever
def vectorize(embeddings):
docs = load_doc()
db = FAISS.from_documents(docs, embeddings)
db.save_local("./opdf_index")
bm25_retriever = BM25Retriever.from_documents(docs)
bm25_retriever.k=5
return db,bm25_retriever
# loads vectorstore from disk and creates BM25 retriever
def load_db():
embeddings = HuggingFaceEmbeddings()
try:
db = FAISS.load_local("./opdf_index", embeddings)
bm25_retriever = BM25Retriever.from_documents(load_doc())
bm25_retriever.k=5
except Exception as e:
print(f'Exception: {e}\nno index on disk, creating new...')
db,bm25_retriever = vectorize(embeddings)
return db,bm25_retriever5. Module 2: Load LLM and Create a QA chain
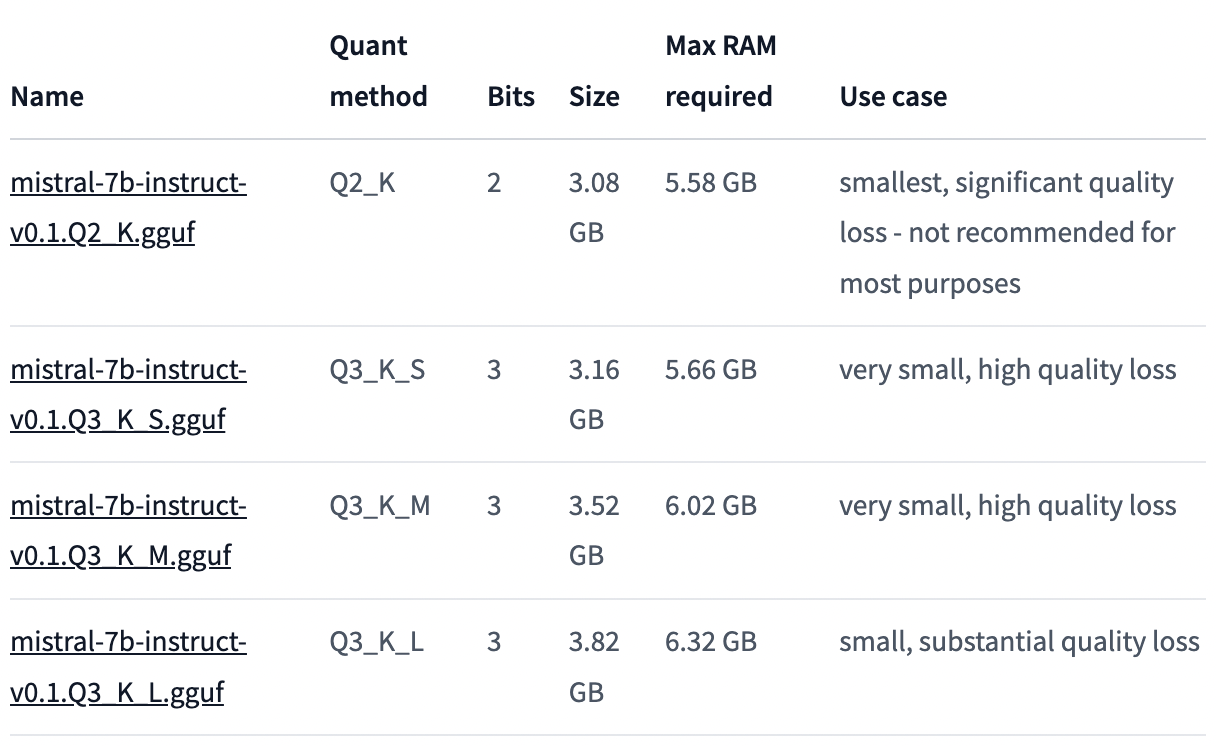
Due to the rather limited resources on my machine, we will use the 2-bit quantized Mistral-7B-instruct model from the TheBloke's Hugging Face repo. As per the following screenshot of TheBloke's repo file listing, this model has the lowest RAM requirement:
To load this model, we will instantiate a LlamaCpp instance with some typical model parameters. The model GGUF file itself was pre-downloaded and saved to a specific directory. We will then create an EnsembleRetriever instance with a FAISS and a BM25 retrievers, initially at weights ratio of 0.5 each. Finally, a RetrievalQA chain is created with the LLamaCpp instance, the ensemble retriever and the prompt. Mistral prompt follows a specific template:
[INST] {context} [/INST]{question}
Accordingly, the following listing captures the full code for this main module.
# main.py
from langchain.retrievers import EnsembleRetriever
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
from langchain.llms import LlamaCpp
import LoadVectorize
import LLMPerfMonitor
import timeit
llm = LlamaCpp(
model_path="./models/mistral_7b_gguf/mistral-7b-instruct-v0.1.Q2_K.gguf",
temperature=0.01,
max_tokens=2000,
top_p=1,
verbose=False,
n_ctx=2048
)
# load document, vectorize and create retrievers
db,bm25_r = LoadVectorize.load_db()
faiss_retriever = db.as_retriever(search_type="mmr", search_kwargs={'fetch_k': 3}, max_tokens_limit=1000)
# instantiate an ensemble retriever
r = 0.5
ensemble_retriever = EnsembleRetriever(retrievers=[bm25_r,faiss_retriever],weights=[r,1-r])
# Prompt template
qa_template = """[INST] You are a helpful assistant.
Use the following context to answer the question below comprehensively:
{context}
[/INST] {question}
"""
QA_PROMPT = PromptTemplate.from_template(qa_template)
# create a retrieval QA Chain
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=ensemble_retriever,
chain_type_kwargs={"prompt": QA_PROMPT}
)
# ask query
query = "What is the purpose of a peering rule on SteelHead?"
result = qa_chain({"query": query})
print(f'Q: {query}\nA: {result["result"]}')6. Module 3: Calculation of Sentence Similarity
This helper module has three methods, where two will be for computing sentence similarity between the generated response and a sample response using cosine and meteor score. The last method is for reading from disk a list of questions for the LLM along with the proposed answers by a subject expert.
# LLMPerfMonitor.py
from sentence_transformers import SentenceTransformer, util
import nltk
from nltk.translate import meteor
from nltk import word_tokenize
# returns a list of questions interleaved with answers
def get_questions_answers():
with open("sh_qa_list.txt") as qfile:
lines = [line.rstrip()[3:] for line in qfile]
return lines
# calculates cosine between two sentences
def calc_similarity(sent1,sent2):
# creates embeddings, computes cosine similarity and returns the value
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# compute embedding for both strings
embedding_1= model.encode(sent1, convert_to_tensor=True)
embedding_2 = model.encode(sent2, convert_to_tensor=True)
return util.pytorch_cos_sim(embedding_1, embedding_2).item()
# calculates meteor score between two sentences
def calculate_meteor_score(response, ref):
reference = ref
hypothesis = response
score = meteor(
[word_tokenize(reference)],
word_tokenize(hypothesis)
)
return score7. Ensemble Retriever's Weights Ratio
To demonstrate the impact of the retrievers on the LLM performance, we will manipulate parameter weights in EnsembleRetriever(retrievers,weights=[r,1-r]) to control the ratio of each retriever's result on the context supplied to the model. When variable r is 0, the preference is entirely for the keyword search for our selected retrievers, whereas when r is 1, the preference is exclusively for semantic similarity.
For an objective evaluation of this experimentation, we will compute cosine similarity as well as the meteor score of model's answers against answers provided by a subject-matter expert. The main module code can be modified to include a for loop to vary the ratio and a nested for loop to iterate through 10 questions through the QA chain, as shown next:
print('model;question;cosine;meteor;exec_time')
# weight ratio, r in [0.0, 0.25, 0.5, 0.75, 1.0]
for r in [x/100 for x in range(0,101,25)]:
ensemble_retriever = EnsembleRetriever(retrievers=[bm25_r,faiss_retriever],weights=[r,1-r])
# QA Chain
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=ensemble_retriever,
chain_type_kwargs={"prompt": QA_PROMPT}
)
qa_list = LLMPerfMonitor.get_questions_answers()
# iterate through a list of questions, qa_list
for i,query in enumerate(qa_list[::2]):
start = timeit.default_timer()
result = qa_chain({"query": query})
# compute cosine similarity, meteor score and execution time
cos_sim = LLMPerfMonitor.calc_similarity(qa_list[i*2+1],result["result"])
meteor = LLMPerfMonitor.calculate_meteor_score(qa_list[i*2+1],result["result"])
time = timeit.default_timer() - start # seconds
# each output starts with the model name in form bm25-_f-<1-r>
print(f'bm25-{r:.1f}_f-{11-r:.1f};{i+1};{cos_sim:.5};{meteor:.5};{time:.2f}') The following output shows a small extract of the result for one weights ratio:
model;question;cosine;meteor;exec_time
bm25-0.0_f-1.0;Q1;0.40948;0.075951;145.35
bm25-0.0_f-1.0;Q2;0.87253;0.21472;99.01
bm25-0.0_f-1.0;Q3;0.85557;0.11558;119.79
bm25-0.0_f-1.0;Q4;0.88227;0.44735;72.56
bm25-0.0_f-1.0;Q5;0.71289;0.090812;130.29
bm25-0.0_f-1.0;Q6;0.80128;0.13992;102.57
bm25-0.0_f-1.0;Q7;0.44649;0.11823;106.07
bm25-0.0_f-1.0;Q8;0.55639;0.013731;155.55
bm25-0.0_f-1.0;Q9;0.49406;0.15182;96.12
bm25-0.0_f-1.0;Q10;0.5471;0.10771;109.918. Results and Findings
Fig.2 below shows the cosine similarity value for different ensemble retriever weight's ratio for 10 tested questions. Each line represents the score of the particular model with the chosen ensemble weights ratio. For instance, model bm25-0.0_f-1.0 represents the QA chain using the ensemble retriever ratios 0.0 for BM25 and 1.0 for FAISS, respectively. For some questions, pure sparse retrieval (bm25-1.0_f-0.0) had the lowest score, such as question #2, whereas for some other questions, it performed on par with others like questions #3 and #5.
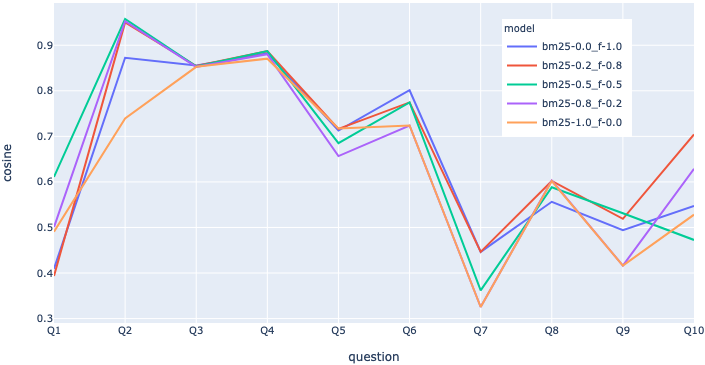
Based on these numeric scores, all variations of ensemble weights ratio appear to have performed poorly against question #7. The question and its sample answer were:
Q: Name two methods supported by WCCP for transmitting packets between a router and SteelHead. A: The GRE encapsulation method and the Layer-2 method.
This question seeks for two supported methods for WCCP packet forwarding. Based on the cosine as well as meteor scores (latter not in chart), sparse retrieval appears to have failed badly here. The similarity search approach did only slightly better. To understand how the response generated by models bm25-0.0_f-1.0 and bm25-1.0_f-0.0 looked qualitatively for this question, here are the actual responses:
<< bm25-0.0_f-1.0 >> Two methods supported by WCCP for transmitting packets between a router and SteelHead are: 1. Either - Use Layer 2 first; if Layer 2 is not supported, GRE is used. This is the default value. 2. GRE - Generic Routing Encapsulation. The GRE encapsulation method
<< bm25-1.0_f-0.0 >> Two methods supported by WCCP for transmitting packets between a router and SteelHead are: 1. Either - Use Layer 2 first; if Layer 2 is not supported, GRE is used. This is the default value. 2. L2 - Layer-2 redirection.
This blew my mind! 🤯 The first model's response is beyond perfect, and this is probably the best answer anyone could provide for this question. The second model repeated the same method as options, but otherwise, its response is not too bad either. If we simply relied on the similarity scores against a sample answer of an expert, we would have missed such amazing responses from Mistral 7B Instruct, just because the choice of words in the response were rather different resulting in lower sentence similarity! Furthermore, the answers to other questions were equally mind-boggling. Considering all these experiments involve the quantized 2-bit model, which should have had a significant quality loss from the original model, this speaks volume to the text understanding and generation capability of this LLM.
From the line chart in Fig. 2, it is not entirely clear which ensemble weights ratio was the best across the questions. To gain a better insight around this aspect, let's adopt a chart that captures the inherent hierarchy in this data. The following treemap chart in Fig. 3 captures cosine variation among the models as well as questions. The enclosing rectangle with the model name includes smaller numbered rectangles from Q1 to Q10 to represent its scores for those questions. The color scale and the square/rectangle area help to highlight the differences in the value. The darker shade squares are questions where the model managed to achieve a cosine higher than 0.7.
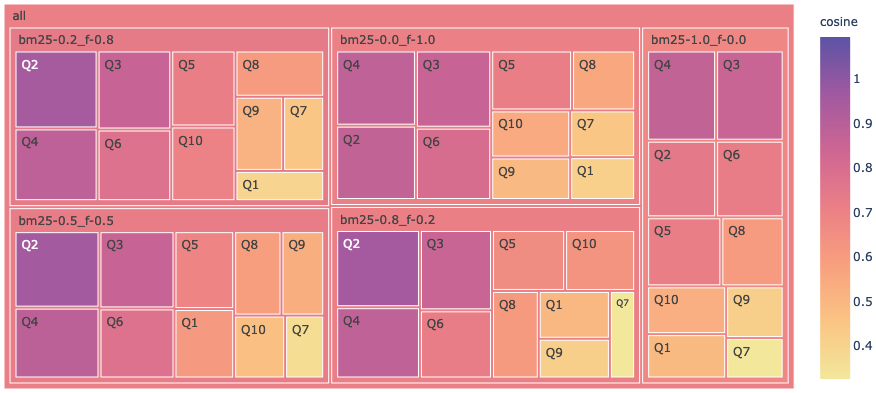
Questions #2 and #4 have the highest cosine across the ratios, which is easily evident from the darkest shaded areas. At the model level, model bm25-0.2_f-0.8 has the highest average score represented by its darkest shade followed by bm25-0.5_f-0.5. On the contrary, the pure sparse bm25-1.0_f-0.0 relying on the keyword search had the lowest average.
This suggests using a weights ratio of 0.25/0.75 or 0.5/0.5 between BM25 and FAISS to query your internal documents may likely result in the best answers.
In addition to the accuracy of the response, execution time of the model is another key criteria for a QA system. Accordingly, the following treemap in Fig. 4 captures metric exec_time in seconds for all the chosen ensemble weights ratios.
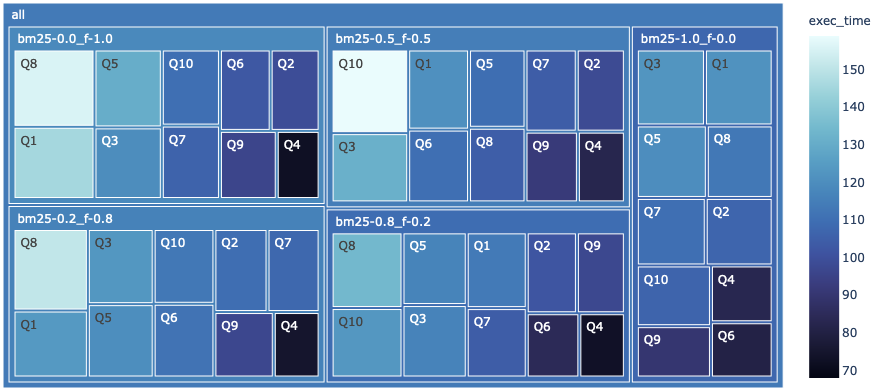
As expected, the model using pure sparse context (bm25-1.0_f-0.0) experienced the lowest execution time, whereas the pure similarity search context (bm25-0.0_f-1.0) is on the opposite end of the spectrum.
I am sure you would agree that the insights from this experiment data increased immensely due to these treemap charts. If you are keen to find out more about such charts and want to build one with Plotly to wow your audience, feel free to check out our article below:
Closing Remarks
As pre-trained LLMs are become larger and better at text generation, the areas of application keeps growing. In its short history, Mistral 7B has been shown to perform very well in different areas and even against some bigger models. In this article, we looked at how to run a quantized version of Mistral 7B Instruct on a consumer grade system using llama-cpp-python. To allow this model to perform well even against possibly unseen internal documents, we adopted an ensemble retriever model that mixes a sparse and dense model to provide the best context for the LLM text generation. Based on this sample of results, we determined that adopting an equal ratio of 0.5 between the sparse and dense retrievers, the model was able to maintain good accuracy as well as has a reasonable run time. More importantly, even at 2-bit quantized version of Mistral 7B-Instruct model when supplemented by context from the the ensemble retriever, the accuracy of its responses were just out of this world!
If you have any feedback, query or would like to see other results, please leave a comment and I will definitely get back in a timely fashion. Thank you for reading!